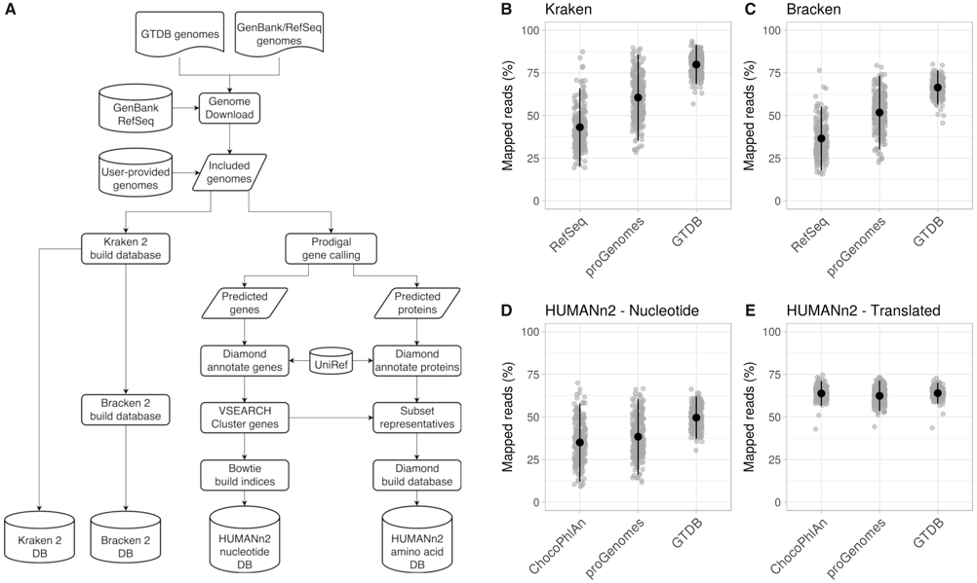
Taxonomic and functional information from microbial communities can be efficiently obtained by metagenome profiling, which requires databases of genes and genomes to which sequence reads are mapped. However, the databases that accompany metagenome profilers are not updated at a pace that matches the increase in available microbial genomes, and unifying database content across metagenome profiling tools can be cumbersome. To address this, we developed Struo, a modular pipeline that automatizes the acquisition of genomes from public repositories and the construction of custom databases for multiple metagenome profilers. The use of custom databases that broadly represent the known microbial diversity by incorporating novel genomes results in a substantial increase in mappability of reads in synthetic and real metagenome datasets.